


Want to know everything about ChatGPT, like what it is and how it works?
ChatGPT is a conversational AI model developed by OpenAI that can generate human-like responses to natural language queries. The model is a Large Language Model (LLM) that uses the transformer architecture to process input data and create output sequences.
This article will tell you what ChatGPT is and how it works. So, without wasting any time, let’s get started.
What is ChatGPT?

OpenAI is a leading research organization. It focuses on developing cutting-edge artificial intelligence (AI) technologies, made ChatGPT, which is a large-scale language model.
They trained the model on a huge amount of text from the internet and other places using cutting-edge deep learning methods. This helped it learn the patterns and structure of human language.
The Birth of ChatGPT
A group of researchers and engineers at OpenAI, including Sam Altman, Greg Brockman, Ilya Sutskever, Wojciech Zaremba, and others, created the ChatGPT model.
OpenAI made the model as part of their larger goal to create AI systems that are safe and helpful and can solve some of the world’s biggest problems.
The first version of ChatGPT came out in June 2018. It was called GPT-1. Several other versions came after it, such as the GPT-2 and GPT-3, which are more advanced and powerful. With more than 175 billion parameters, GPT-3, which came out in June 2020, is one of the largest and most powerful language models today.
Over the past ten years, progress in deep learning and natural language processing (NLP) has made it possible to create ChatGPT.
Thanks to these technologies, researchers have been able to train large-scale language models on vast amounts of data. This has led to significant advances in the field of AI.
You can use ChatGPT for many things, such as understanding natural language, translating languages, creating chatbots, and generating content.
People can also use it to make text that sounds like they wrote.
This includes news articles, stories, and poems. Its ability to interpret and compose human-sounding language could alter several industries and make computers and other digital gadgets easier to use.
Before we move on to how ChatGPT works, let’s first understand LLMs and Transformers.
Large Language Models
Large Language Models (LLMs) are machine learning models used in Natural Language Processing to infer relationships between words within a large dataset.
LLMs have gained popularity in recent years due to advances in computational power, which enable larger input datasets and parameter spaces. The most basic form of training for LLMs involves predicting a word in a sequence of words.
There are two standard techniques for this:
- Next-token prediction
- Masked language modeling
Next-token prediction involves predicting the next word in a sequence given the context of the previous words.
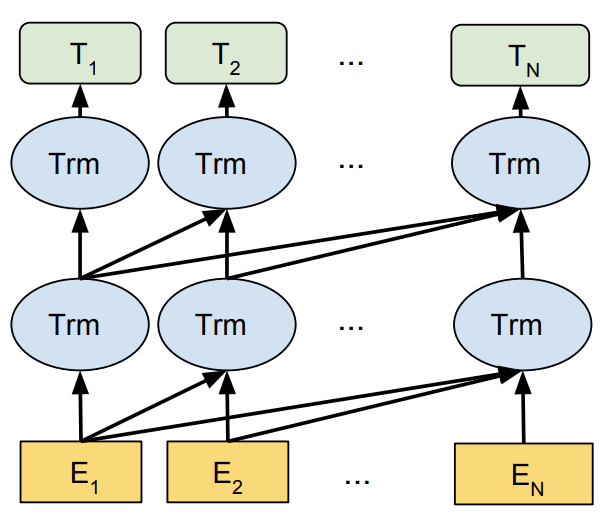
Masked language modeling involves masking out a word in a sequence and predicting what the masked word is based on the context of the other words.
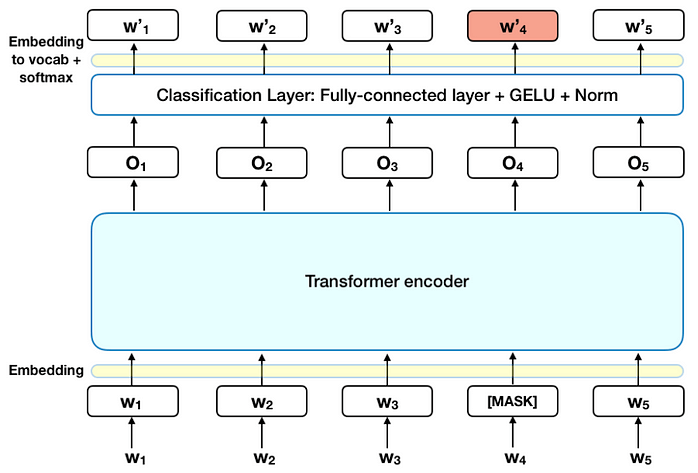
These techniques are typically deployed through a Long-Short-Term-Memory (LSTM) model.
However, LSTMs have limitations.
They process input data individually and sequentially. The model cannot value some of the surrounding words more than others. In response to these issues, transformer architecture was introduced.
Transformers and Self-Attention
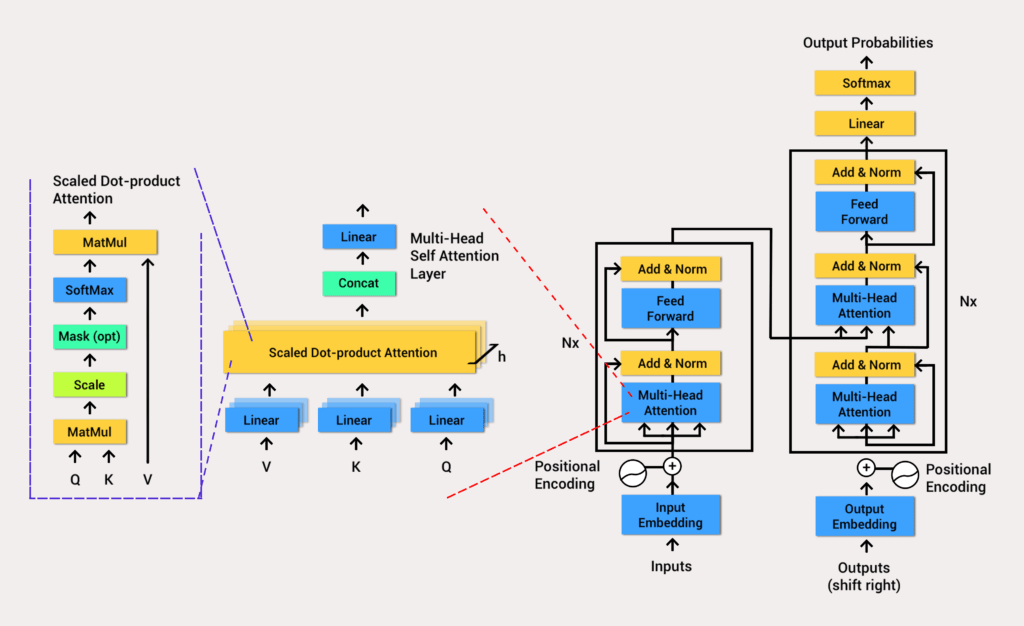
Transformers are a type of neural network architecture that can process all input data simultaneously.
The model uses a self-attention mechanism to give varying weight to different parts of the input data about any position of the language sequence.
Self-attention enables the processing of significantly larger datasets and allows for more complex relationships between words.
Generative Pre-training Transformer (GPT) models use the transformer architecture with an encoder to process the input sequence and a decoder to generate the output sequence.
The encoder and decoder have a multi-head self-attention mechanism that allows the model to differentially weight parts of the sequence to infer meaning and context.
The self-attention mechanism works by converting tokens (pieces of text) into vectors that represent the importance of the token in the input sequence.
The multi-head attention mechanism GPT uses iterations the self-attention mechanism several times, generating a new linear projection of the query, key, and value vectors.
This enables the model to grasp sub-meanings and more complex relationships within the input data.
How ChatGPT Works (All You Need to Know)
To understand how ChatGPT works, we need to break down the process step by step.
Step 1: Training Data
The engineers at Open AI trained ChatGPT on a massive amount of text data, including books, articles, and web pages.
The model uses this training data to learn how to understand and generate human-like responses to a wide range of input.
Step 2: Preprocessing
It needs to preprocess the training data before feeding it into the model to ensure it can understand it.
Tasks such as tokenization involve breaking down each word in the text into a separate “token,” encoding represents each token as a numerical value that the model can work with.
Step 3:Training
Once the data has been preprocessed, it can be fed into the model for training. During training, the model adjusts its internal parameters to fit better the patterns and structure of the fed text data.
The model learns from its mistakes and makes incremental improvements through backpropagation.
Step 4: Inference
Once it trains the model, you can use it for inference, which involves generating responses to natural language input.
When a user enters text into ChatGPT, the model uses its internal parameters to generate a response that it believes is most likely human-like.
Step 5: Evaluation
To ensure that the responses generated by ChatGPT are of high quality, the model is regularly evaluated using various metrics and tests.
Identifying areas where the model may be making mistakes or struggling to generate accurate responses helps improve the model’s performance over time.
Well, the above explanation is just a significantly simpler one.
Let’s dive deep into ChatGPT’s background processing and how it generates data, which we all see on the front end.
How ChatGPT Generates Response?
The GPT model has already been trained on extensive text data collection, such as Wikipedia, books, and web pages.
During the pre-training phase, the model learns to predict the next word in a sentence based on the words that came before it.
This is called modeling language. The GPT model learns to understand human language’s statistical patterns and subtleties by training on a huge amount of data.
After pre-training the model, you can fine-tune it for a specific task, such as a chatbot conversation.
During fine-tuning, the model undergoes training on a smaller dataset of conversations that pertain to the chatbot’s domain.
During the fine-tuning process, we changed the model’s parameters to make the chatbot produce text that is more relevant to its domain.
The GPT model is used to make a chatbot, which has two main steps:
1. Input processing
The chatbot processes the user’s input to extract the intent of the user’s message.
The intent represents the user’s desired action or information.
The input processing step typically involves tokenizing the user’s message into a sequence of words, mapping the words to their corresponding vectors, and passing them through a neural network to predict the intent.
2. Response generation
Once the intent is identified, the GPT model generates a response based on the intent and the conversation context.
The response generation step involves using the GPT model to generate a sequence of words that follow the context of the conversation and are relevant to the user’s intent. The response generation step typically involves sampling from the GPT model’s probability distribution over the next word given the previous words.
Once the intent is determined, the GPT model generates a response by considering both the intent and the ongoing conversation.
During the response creation process, the GPT model constructs a coherent sequence of words that align with the conversation’s context and address the user’s query.
In most instances, generating a response entails selecting a word from the GPT model’s probability distribution for the next word. This selection is based on the preceding words in the conversation.
Using a softmax function, the model transforms its output into a probability distribution over the vocabulary. It selects the next word based on the probability distribution and feeds it into the model as input.
The GPT model is made to make text that makes sense and uses correct grammar. But the model isn’t perfect and sometimes gives answers that don’t make sense or are off-topic.
To deal with this, chatbot developers can filter out inappropriate answers, use user feedback to improve the model, or use rules-based logic to control the model’s output.
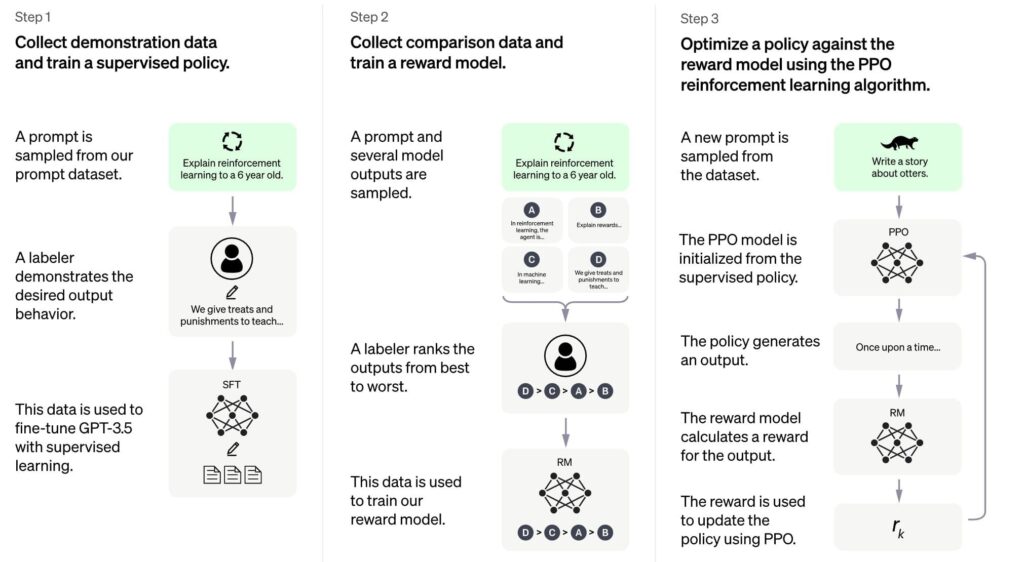
ChatGPT: Learning from Human Feedback
ChatGPT is a spinoff of InstructGPT, which introduced a novel approach to incorporating human feedback into the training process.
The technique is called Reinforcement Learning from Human Feedback (RLHF). RLHF enables the model to learn from human feedback in real time, which improves the model’s ability to align with user intentions and produce helpful and accurate responses.
RLHF works by presenting the user’s input and the model’s response to a human operator who can provide feedback on the quality of the answer.
The team utilizes the feedback to update the model’s parameters, enhancing its capability to generate precise responses in the future.
ChatGPT also includes additional innovations, such as a dialogue manager that ensures coherence between responses and a sentiment classifier that filters out toxic or offensive content.
These innovations make ChatGPT one of the most advanced conversational AI models available today.
How to Use ChatGPT (Basics)
It is not hard to use ChatGPT; for this guide, we have kept the tutorial of using ChatGPT a bit straightforward without going into much detail. However, look out for our complete tutorial on using ChatGPT for more information.
For now, let’s get started:
Create a ChatGPT Account
To use ChatGPT, first, you need to make an account. Go to the website or app and look for the “Sign Up” button.
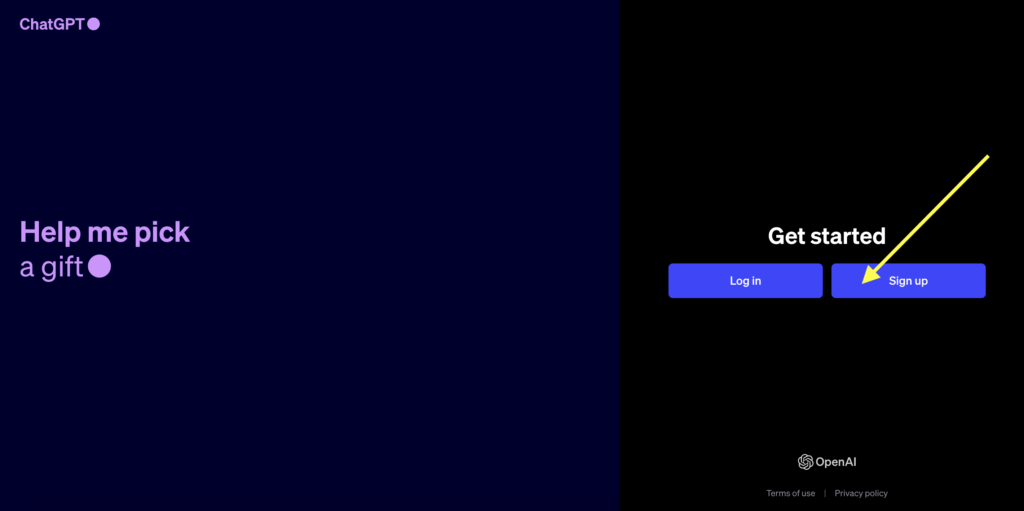
Click it.
You can use your email or Google account to sign up. If you use email, you might have to check it with your phone number. If you already have an account, click “Log In” instead.
Note
Want to know how to create a ChatGPT account in more detail? Please read our guide on creating a ChatGPT account.
Log In and Get Started
Once you have an account, log in.
You will see a place where you can type messages.
This is how you talk to ChatGPT.
Ask Your First Question
Type something you want to ask or say in the message box.
Then press “Enter” on your keyboard. In a few seconds, ChatGPT will answer you.
Do More With the Answer
After you get an answer, you can do different things:
- Ask another question.
- If you don’t like the answer, ask ChatGPT to try again.
- If you like the answer, you can copy it.
- You can also share the answer with friends.
Make ChatGPT Remember Things
One cool thing about ChatGPT is that it can remember what you talked about. So, you can ask new things without repeating the old things.
But remember, it can only remember a few pages of text. So, if you talk a lot, it might forget some old stuff.
Get a New Answer
You can ask for a new one if you don’t like an answer.
Look for a button that says “Regenerate Response” and click it.
Copy and Share
If you like an answer, you can copy it easily. Next to the answer, a small icon will look like a clipboard.
Click it to copy the answer.
You can also share your chat by clicking an “up arrow” icon.
Like or Dislike Answers
You can also say if you like or don’t like an answer. This helps ChatGPT learn. Click the “thumbs up” if you like it or “thumbs down” if you don’t. You can also write why you liked or didn’t like it.
Be Safe
Remember, ChatGPT won’t answer bad or unsafe questions.
So, keep it nice and safe. Also, don’t share private things like passwords.
Check Your Past Chats
You can see old chats on the side of the screen. If you don’t want this, turn it off in “Settings.”
Delete Chats
If you want, you can delete old chats.
Go to “Settings” and look for “Clear Conversations“. Exercise caution, as deleting them will result in their permanent removal.
That’s it! Now you know how to use ChatGPT.
Have fun chatting!
What ChatGPT Can Do?
By now, you might have got an idea of how ChatGPT works. The one question that’s asked often is what ChatGPT is capable of.

So, here’s a list of all the things ChatGPT can do:
- Text generation: ChatGPT can generate human-like text by predicting the most probable next word or sentence based on the input text.
- Language translation: ChatGPT can translate text from one language to another by generating a sequence of words in the target language that best conveys the meaning of the input text.
- Sentiment analysis: ChatGPT can analyze the sentiment of a piece of text, determining whether it expresses positive, negative, or neutral opinion.
- Question answering: ChatGPT can answer questions posed in natural language by generating a response based on its knowledge of the topic.
- Text classification: ChatGPT can classify text into predefined categories based on its content.
- Named entity recognition: ChatGPT can identify and classify named entities (such as people, organizations, and locations) in a text.
- Chatbot development: You can use ChatGPT to develop chatbots that engage in natural language conversations with users.
- Text summarization: ChatGPT can summarize long pieces of text by generating a shorter version that captures the main points.
There are more cool things that you can do on ChatGPT, like coding, fixing bugs, writing poems or songs, and even writing essays or books, that too in any style you want.
But to tell ChatGPT what you want it to do for you, you need to know about prompts.
Let’s discuss what prompts are in ChatGPT and why they are important.
What are Prompts in ChatGPT?
ChatGPT prompts are crucial for generating useful and relevant outcomes from the language model. A prompt is a statement or question provided to ChatGPT, which the model then uses to generate a response.
The importance of prompt engineering lies in crafting specific, clear, and unambiguous prompts so that ChatGPT can produce accurate and relevant outputs.
Prompt engineering involves designing, creating, and evaluating prompts for conversational AI models.
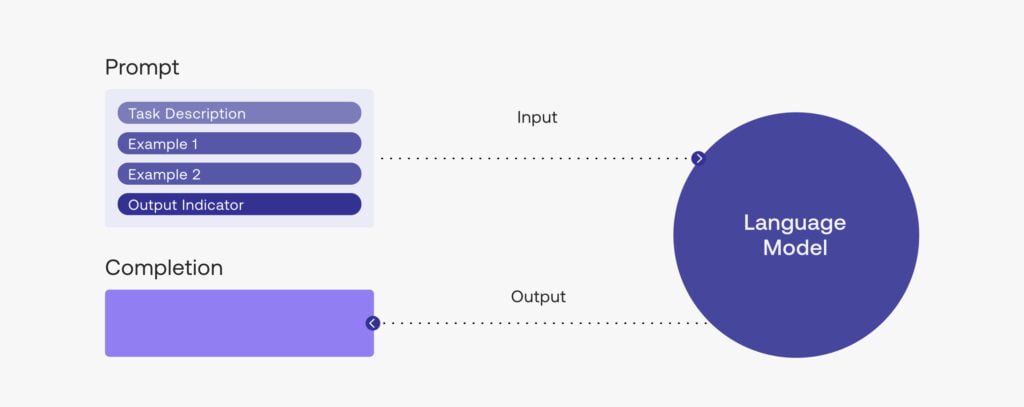
Prompt engineering aims to create high-quality, informative, and engaging prompts that can elicit relevant and accurate responses from ChatGPT.
The design of a prompt is critical in guiding the model towards the desired output.
Carefully constructing the prompt is crucial to provide ChatGPT with the required information to generate accurate and relevant responses.
Understanding how ChatGPT is trained to create a well-crafted prompt is important.
Zero-Shot, One Shot & Few Shot Learning
The model is trained using zero-shot, one-shot, and few-shot learning, which enables it to recognize and classify new objects or concepts with limited or no training examples.
Zero-shot learning refers to ChatGPT’s ability to recognize and classify new objects or concepts it has never seen before, relying on its understanding of related concepts.
For instance, a zero-shot learning model trained on different dog breeds might be able to classify a new breed it has never seen before based on its understanding of the attributes of dog breeds.
On the other hand, one-shot learning refers to ChatGPT’s ability to recognize and classify new objects or concepts with only one training example.
For instance, a single image could train a one-shot learning model to identify an individual’s face.
Few-shot learning refers to ChatGPT’s ability to recognize and classify new objects or concepts with a small number of training examples.
For instance, one could train a few-shot learning model to identify different types of fruits using only a few training examples of each type.
Check this:
Check this guide on prompt engineering: How To Write Better ChatGPT Prompts To Get Better Results?
One of the benefits of prompt engineering is that it enables us to modify ChatGPT’s responses.
For example, if ChatGPT generates a dumb response, we can modify the prompt to provide a more informative question or statement to guide the model toward the desired output.
Prompt engineering also allows us to train ChatGPT to respond to specific questions or prompts.
For instance, we can use one-shot or few-shot learning to provide examples of the outcome we want in the prompt.
This helps ChatGPT generate more accurate and relevant responses.
Best And Worst Part of ChatGPT
Everyone around the world is almost a fan of ChatGPT. However, no one knows what ChatGPT does the best and what it lacks.
But not anymore. Let’s now understand what ChatGPT is best used for and what ChatGPT is bad at.
ChatGPT is Best Used For:
ChatGPT is Bad At:
Watch This to Learn More About ChatGPT
Now You Know What is ChatGPT!
ChatGPT is a powerful tool that can assist with a wide range of tasks, from answering questions to generating text.
However, to get the best results, it’s important to understand how the model works and how to use prompts effectively. Prompt engineering, including zero-shot, one-shot, and few-shot learning, can help improve response quality and ensure the model works as intended.
While ChatGPT constitutes just one part of artificial intelligence, it represents exciting progress in natural language processing. Therefore, understanding its functioning can hold immense value for individuals intrigued by AI and its potential uses.
If you want to learn more about prompts, you can check out some of the best resources on our website:
More Read

Sources






{kind=link}