


OpenAI, a leading name in the AI industry, has unveiled its new web crawling bot, GPTBot, to broaden the dataset for training future AI systems, possibly including the next version named “GPT-5,” as indicated by a recent trademark application.
Gathering Public Data

The newly released GPTBot will collect publicly accessible data from websites while steering clear of paywalled, sensitive, and prohibited content.
This web crawler functions similarly to those of search engines like Google and Bing, assuming that accessible information is fair for use.
To block the OpenAI web crawler from accessing a site, the owner must add a “disallow” rule to a file on their server.
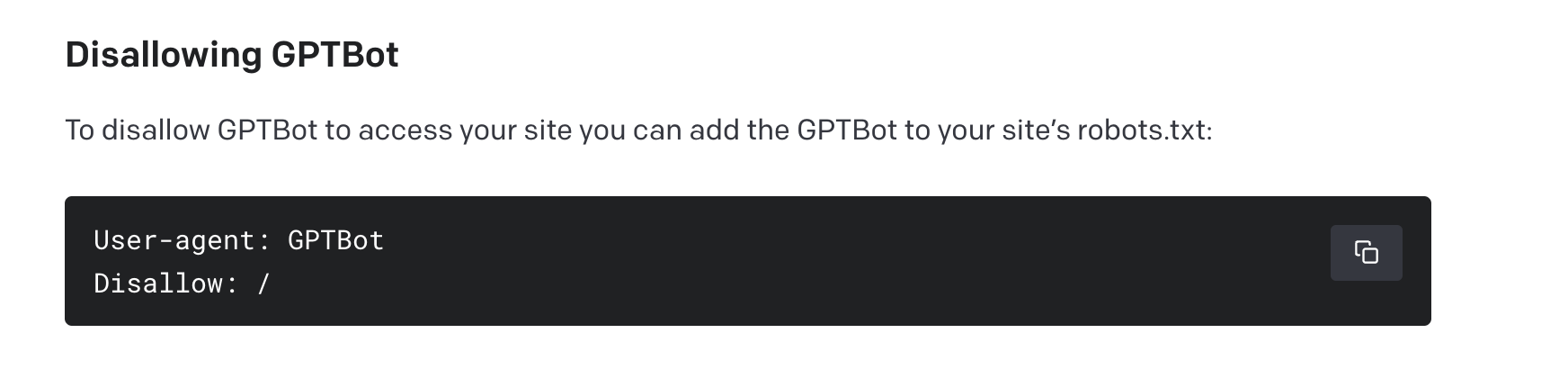
OpenAI has assured that GPTBot will scan the scraped data to eliminate any personally identifiable information (PII) or text that contradicts its policies.
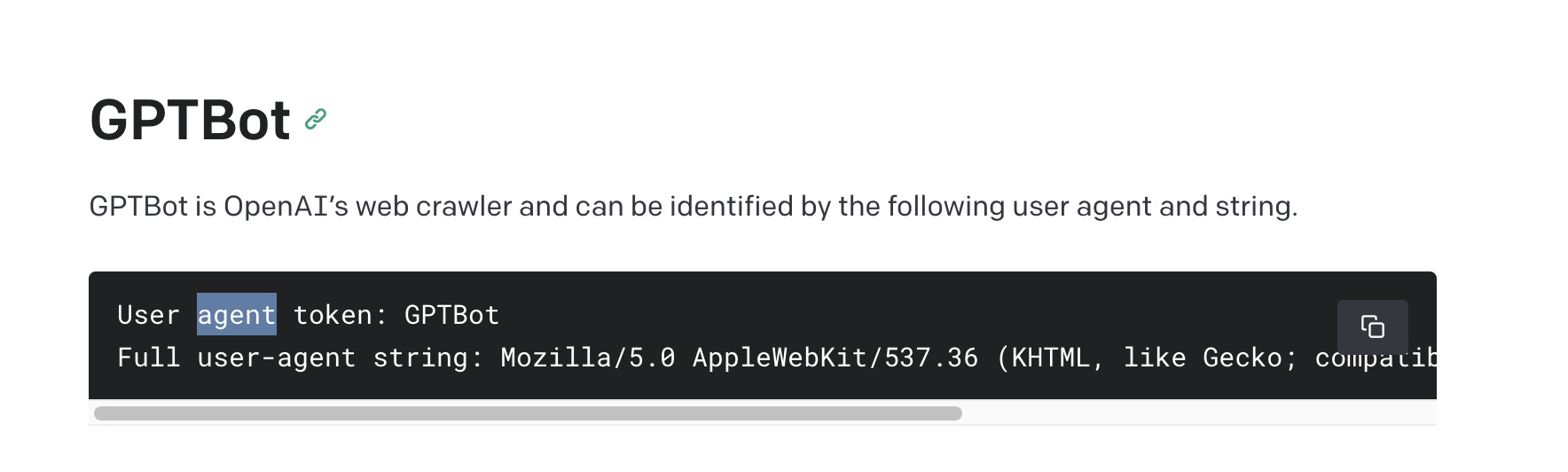
However, the opt-out approach is generating ethical concerns around consent. Critics argue that OpenAI’s actions might lead to derivative work without proper citation.
Addressing Past Controversies
The launch follows prior criticism where OpenAI was accused of scraping data without permission for training its Large Language Models (LLMs) like ChatGPT.
In response, OpenAI updated its privacy policies in April.
The new web crawler represents OpenAI’s need for more current data to maintain and enhance its LLMs.
The move may indicate a shift from OpenAI’s initial focus on transparency and safety, understandable as ChatGPT remains the most used LLM globally.
OpenAI’s products heavily rely on the quality of data used for training, and the GPTBot aims to gather that essential data.
Competition in the AI Space
Meta, the social media titan, has also been working on AI, offering its model for free unless used by competitors or large businesses.
While OpenAI’s strategy revolves around using crawled data for profitable AI tool ecosystems, Meta aims to build a profitable business around its data.
OpenAI’s ChatGPT currently boasts over 1.5 billion monthly active users, and Microsoft’s $10 billion investment in OpenAI is paying off, as ChatGPT integration has enhanced Bing’s capabilities.
As OpenAI’s GPTBot represents an advancement in AI capabilities, it also reopens copyright, consent, and ethics debates.
As AI systems become more advanced, striking the right balance between transparency, ethics, and technological capability will continue to challenge industry leaders.
The new web crawler’s launch highlights the complexities of innovation in the AI space, where benefits in efficiency and ability may come with potential ethical trade-offs.






{kind=link}